在當(dāng)今人工智能蓬勃發(fā)展的時代,大模型與知識圖譜的結(jié)合正成為推動認知智能縱深發(fā)展的關(guān)鍵技術(shù)路徑。知識圖譜以其強大的結(jié)構(gòu)化知識表示與推理能力,為大模型提供了堅實的知識底座,而大模型則以其卓越的自然語言理解與生成能力,極大地賦能了知識圖譜的構(gòu)建與應(yīng)用。本文將深入探討如何在大模型的驅(qū)動下,高效構(gòu)建知識圖譜,涵蓋從核心理論、技術(shù)選型到工程落地的完整實踐指南。
一、 核心理念:大模型與知識圖譜的協(xié)同增效
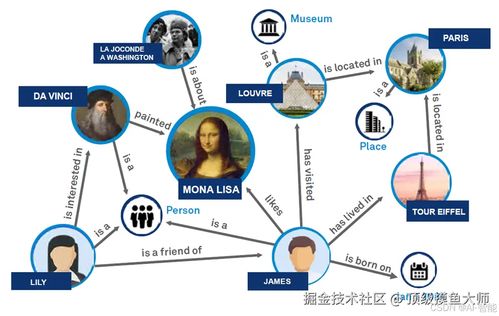
大模型(如GPT、文心一言、通義千問等)與知識圖譜并非替代關(guān)系,而是互補與協(xié)同的“雙引擎”。
- 大模型賦能知識圖譜構(gòu)建:傳統(tǒng)知識圖譜構(gòu)建嚴(yán)重依賴人工規(guī)則與標(biāo)注,成本高昂且擴展性差。大模型憑借其深厚的語言知識,可以自動化或半自動化地完成實體識別、關(guān)系抽取、屬性填充、知識融合等核心任務(wù),顯著提升構(gòu)建效率與規(guī)模。
- 知識圖譜增強大模型能力:大模型雖知識廣博,但存在“幻覺”、事實性錯誤和可解釋性差等問題。知識圖譜作為結(jié)構(gòu)化的“事實記憶庫”,可以為大模型提供精確、可靠、可追溯的知識來源,用于事實核查、增強推理、提升回答的準(zhǔn)確性與可信度。
二、 技術(shù)架構(gòu)與核心模塊
一個典型的大模型驅(qū)動型知識圖譜構(gòu)建與應(yīng)用系統(tǒng),通常包含以下核心模塊:
- 數(shù)據(jù)獲取與預(yù)處理模塊:
- 數(shù)據(jù)源:包括非結(jié)構(gòu)化文本(新聞、報告、論文)、半結(jié)構(gòu)化數(shù)據(jù)(網(wǎng)頁表格、JSON)和結(jié)構(gòu)化數(shù)據(jù)(數(shù)據(jù)庫)。大模型尤其擅長處理非結(jié)構(gòu)化文本。
- 預(yù)處理:文本清洗、分句、分詞等,為后續(xù)信息抽取做好準(zhǔn)備。
- 大模型驅(qū)動的信息抽取模塊(核心):
- 實體識別與鏈接:利用大模型的Few-shot/Zero-shot能力,或通過微調(diào)(Fine-tuning)特定領(lǐng)域模型,識別文本中的實體(如人物、機構(gòu)、概念),并將其鏈接到知識圖譜中的已有節(jié)點。
- 關(guān)系與屬性抽取:通過精心設(shè)計的提示詞工程(Prompt Engineering),引導(dǎo)大模型從句子或段落中抽取出實體間的語義關(guān)系(如“創(chuàng)始人”、“位于”)及實體的屬性(如“成立日期”、“注冊資本”)。
- 事件抽取:對于更復(fù)雜的動態(tài)知識,可抽取事件(如“公司上市”、“產(chǎn)品發(fā)布”)及其相關(guān)要素(時間、地點、參與者)。
- 知識融合與存儲模塊:
- 知識融合:對不同來源抽取的、可能存在沖突或冗余的知識進行對齊、消歧與合并。大模型可以輔助進行實體消歧和沖突消解。
- 知識存儲:將結(jié)構(gòu)化后的知識存入圖數(shù)據(jù)庫(如Neo4j, Nebula Graph, JanusGraph)或RDF三元組庫,形成可查詢、可推理的知識圖譜。
- 知識推理與應(yīng)用模塊:
- 推理與補全:基于圖譜的拓撲結(jié)構(gòu),利用規(guī)則或嵌入表示進行隱含關(guān)系推理,補全缺失知識。
- 智能應(yīng)用:
- 增強檢索(RAG):將知識圖譜作為外部知識源,與大模型結(jié)合,實現(xiàn)精準(zhǔn)、可溯源的問答系統(tǒng)。
- 決策支持:在金融、醫(yī)療、政務(wù)等領(lǐng)域,提供基于深度關(guān)系的分析與洞察。
- 語義搜索:超越關(guān)鍵詞匹配,實現(xiàn)基于實體和關(guān)系的精準(zhǔn)語義搜索。
三、 實戰(zhàn)流程與開發(fā)要點
第一步:定義領(lǐng)域與模式
明確知識圖譜的應(yīng)用場景(如企業(yè)風(fēng)控、醫(yī)療診斷、智能客服),設(shè)計本體(Ontology),即定義實體類型、關(guān)系類型和屬性體系。這是圖譜的“骨架”。
第二步:技術(shù)選型與數(shù)據(jù)準(zhǔn)備
- 大模型選擇:根據(jù)領(lǐng)域?qū)I(yè)性、成本、性能需求,選擇通用大模型API(如OpenAI GPT-4, 國內(nèi)主流平臺API)或開源可微調(diào)模型(如LLaMA系列、ChatGLM、Qwen)。領(lǐng)域性強的任務(wù)建議進行有監(jiān)督微調(diào)。
- 圖數(shù)據(jù)庫選擇:根據(jù)數(shù)據(jù)規(guī)模、查詢復(fù)雜度、并發(fā)需求選擇。Neo4j適合快速原型和豐富的關(guān)系查詢;Nebula Graph適合超大規(guī)模分布式場景。
第三步:實現(xiàn)信息抽取流水線
- Prompt設(shè)計:這是與大模型交互的核心。設(shè)計清晰、具體、包含示例(Few-shot)的提示詞,明確指令、輸入格式和輸出格式(如要求輸出標(biāo)準(zhǔn)JSON)。例如:“請從以下句子中抽取出所有公司實體和它們之間的關(guān)系。關(guān)系類型限定為:投資、競爭、合作。以JSON格式輸出:{"entities": [...], "relations": [...]}”。
- 任務(wù)分解:復(fù)雜任務(wù)可拆分為“實體識別→關(guān)系分類”等多個子步驟鏈?zhǔn)秸{(diào)用,以提高準(zhǔn)確性。
- 后處理與校驗:設(shè)計規(guī)則或利用小規(guī)模標(biāo)注數(shù)據(jù)對模型輸出進行清洗、格式化與質(zhì)量校驗。
第四步:構(gòu)建、存儲與維護圖譜
- 將抽取的(實體,關(guān)系,實體)三元組和實體屬性批量導(dǎo)入圖數(shù)據(jù)庫。
- 建立定期的知識更新與迭代機制,實現(xiàn)圖譜的動態(tài)演化。
第五步:開發(fā)上層應(yīng)用
- 利用圖查詢語言(如Cypher, nGQL)從圖譜中檢索信息。
- 構(gòu)建應(yīng)用接口,將圖譜檢索結(jié)果與大模型的生成能力結(jié)合,打造最終應(yīng)用。
四、 挑戰(zhàn)與未來展望
- 挑戰(zhàn):大模型生成的不穩(wěn)定性與成本控制;復(fù)雜、隱含關(guān)系的抽取精度;海量知識下的高效存儲與檢索;領(lǐng)域知識的持續(xù)注入與更新。
- 展望:大模型與知識圖譜的融合將更加緊密。向量數(shù)據(jù)庫將與圖數(shù)據(jù)庫結(jié)合,形成“向量-圖”混合存儲,同時支持語義相似性搜索與復(fù)雜關(guān)系推理。自監(jiān)督學(xué)習(xí)、強化學(xué)習(xí)將進一步優(yōu)化知識抽取與推理過程,推動面向復(fù)雜場景的“認知智能系統(tǒng)”走向成熟。
構(gòu)建大模型驅(qū)動的知識圖譜,是一場將非結(jié)構(gòu)化信息轉(zhuǎn)化為可計算、可推理的結(jié)構(gòu)化知識的系統(tǒng)工程。它不僅是技術(shù)的融合,更是對業(yè)務(wù)深刻理解的體現(xiàn)。從明確場景出發(fā),以小步快跑的方式迭代驗證,方能真正釋放“大模型+知識圖譜”的聯(lián)合價值,賦能千行百業(yè)的智能化轉(zhuǎn)型。